To those who regard the NHL playoffs as a competition designed to determine the league’s best team, the result can mean only one thing – that the Bruins were the best team all along, and the Canucks mere pretenders.
A more reasonable explanation, however, is that shit happens over the course of a seven game series and, because of that, the better team doesn’t always win. The Canucks were better than Boston during the regular season, and were likely better in the first three rounds of the playoffs as well. They were better than Boston last year and there’s a good chance that they’ll do better next year. They were probably the better team.
The Canucks may or may not have been the best team in the league, but if they were in fact better than Boston, then that means that a team other than the best team in the league won the cup. That raises an interesting question – how often does the best team in the league end up winning the cup?
(The answer, of course, will vary as a function of the level of parity that exists in the league. Because the level of league parity has varied over time as a function of era, we’ll confine our answer to the post-lockout years).
Unfortunately, the question cannot be answered directly due to the fact that it’s not possible to identify the league’s best team in any given season with any certitude. One can only speak in terms of probability and educated guesses.
It is, however, possible to arrive at an approximate answer through assigning artificial win probabilities to each team, simulating a large number of seasons, and looking at how often the team with the best win probability ends up winning the cup.
This exercise is made possible by the fact that the distribution in team ability – which we’ll define as true talent goal ratio –can be ascertained through examining the observed spread in goal ratio and identifying the curve which best produces that spread when run through the appropriate simulator.
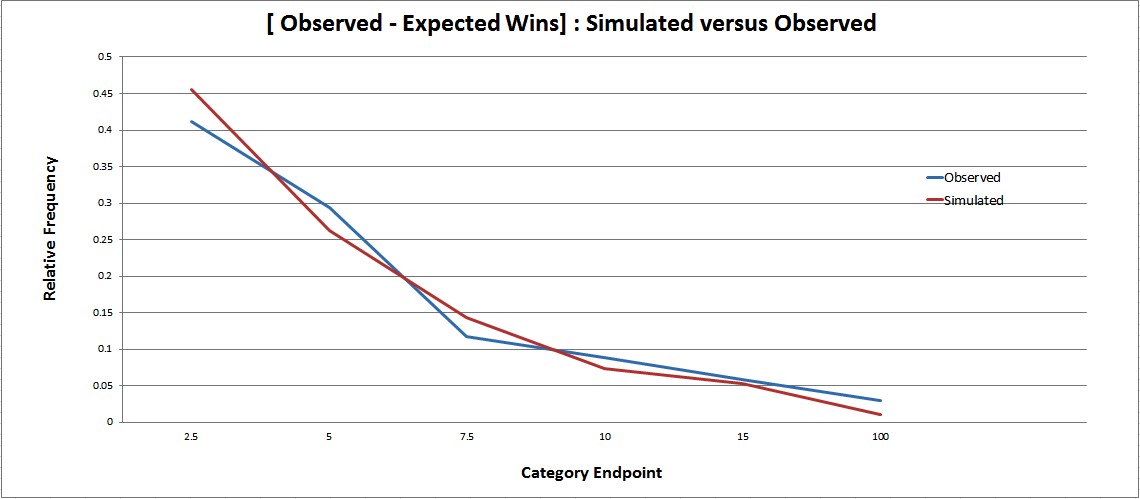
In order to generate an observed distribution of results, I randomly selected 40 games from every team and looked at how each of them performed with respect to goal percentage (empty netters excluded) over that sample. This exercise was performed 2000 times for each of the six post lockout seasons. The following curve resulted:

The likely ability distribution is the curve shown below – a normal distribution with a mean of 0.5 and standard deviation of 0.03.

If a large number of half-seasons are simulated through assigning artificial goal percentages based on the above ability distribution, the spread in simulated results closely matches the observed results displayed in the first graph.

As the ability distribution can be used to generate results that closely parallel those observed in reality, it can also be used in order to answer the question posed earlier in the post – that is, the probability of the best team in the league winning the cup in any given season.
Here’s how the simulations were conducted:
- For each simulated season, every team was assigned an artificial goal percentage based on the ability distribution produced above
- The artificial goal percentages were, in turn, used to produce GF/game and GA/game values for each team
- GF/game values were calculated by multiplying a team’s goal percentage by 5.49 (5.49 being the approximate average number of non empty net goals scored per game in the post-lockout era)
- GA/game values were calculated by subtracting a team’s GF/game value from 5.49
- All 1230 games from the 2010-11regular season were then simulated, with a score being generated for each individual game
- The probability of a team scoring ‘x’ number of goals in an individual game was determined through taking its GF/game value and adjusting it based on the GA/game value of the opponent
- If each team scored an equal number of goals, each team was awarded one point and a random number generator was used to determine which of the two teams received the additional point
- After all games were simulated, the division and conference standings were determined in accordance with NHL rules (that is, with the teams ranked by points, with the division winners being placed in the first three seeds in each conference)
- If two teams were tied in points, greater number of wins was used as a tiebreaker
- If two teams had the same number of points and wins, then a random number generator was used as a second tiebreaker
- The playoff matchups were then determined based on the regular season standings
- Individual playoff games were not simulated; rather, each series was simulated as a whole based on the Pythagorean expectations (which were derived from the goal percentage values) of the involved teams
- Home advantage for the higher seed was valued at +0.015
20 000 Simulations were conducted in total. Here’s how the league’s best team – defined as the team with the best underlying goal percentage in each individual season – fared. We’ll start with the regular season results:

The above chart shows how the best team performed in four areas – division rank, conference rank, league rank in points, and league rank in goal differential. So, as an example, the best team ended up winning the President’s Trophy – i.e. finishing with the most points – about 32% of time.
The results are interesting. The best team does very well in general, but the range in outcomes is considerable. It wins its division a majority of the time yet still manages to finish dead last every now and then (about once every 200 seasons). It wins the conference almost half the time and finishes in the top four about 84% of the time. However, it still misses the playoffs a non-trivial percentage of the time (2.2%). The latter fact may not be too surprising – the 2010-11 Chicago Blackhawks were close to being the best team in the league but only made the playoffs by the slimmest of margins.
It wins the President’s Trophy about a third of time and does even better in terms of goal differential, posting the best mark in roughly 40% of the simulations. However, it occasionally finishes in the bottom half of the league in both categories (about 2% and 1% of the time, respectively).
The graph below shows the distribution in year end point totals for the best team. It averaged just over 107 points, with a high of 145 and a low of 73.

And the distribution in goal differential (mean = 57; max = 161; min= -34).

Finally, the chart showing the playoff outcomes for the best team, and therefore answering the question posed earlier.

It turns out that the best team wins the cup 22% of the time – about once every five seasons. This accords well with what we’ve observed since the lockout, with the 2007-08 Detroit Red Wings being the only cup winner that was also unambiguously the best team in the league. The 2009-10 Chicago Blackhawks were probably the best but it’s hard to say for sure. The 2008-09 Penguins were a good team but the Wings were probably better that year. Ditto for the 2006-07 Ducks. The 2010-11 Bruins were merely a good team, and I can’t even say that much for the 2005-06 Hurricanes, who may not have even been one of the ten best teams in the league during that season.
Caveats:
The exercise assumes that team ability is static. This is obviously untrue in reality, given injuries, roster turnover, and like variables. Consequently, the best true talent team at one point in the season may not be the best team at a different point. Moreover, the spread in team talent at any given point in the season is likely to be somewhat broader than the ability curve used in the exercise.
Scores were generated for individual games through the use of poisson probabilities, which does not take into account score effects. Thus, the model slightly underestimates the incidence of tie games. For the same reason, it also overestimates the team-to-team spread in goal differential.





























{kind=link}
{kind=link}
{kind=link}